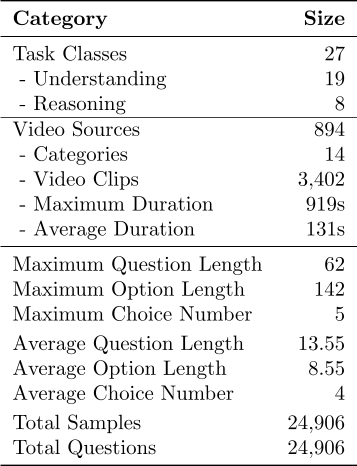
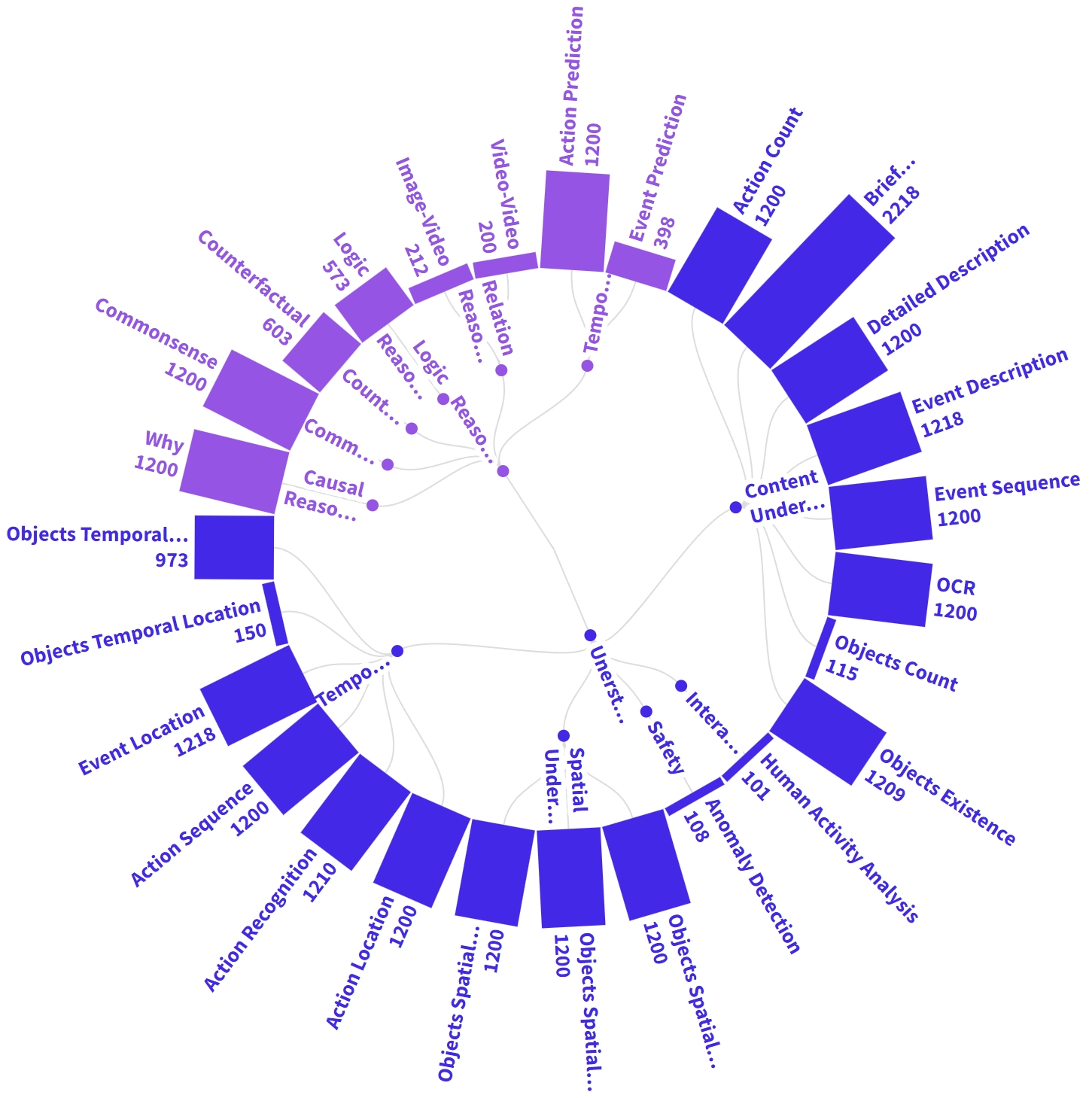
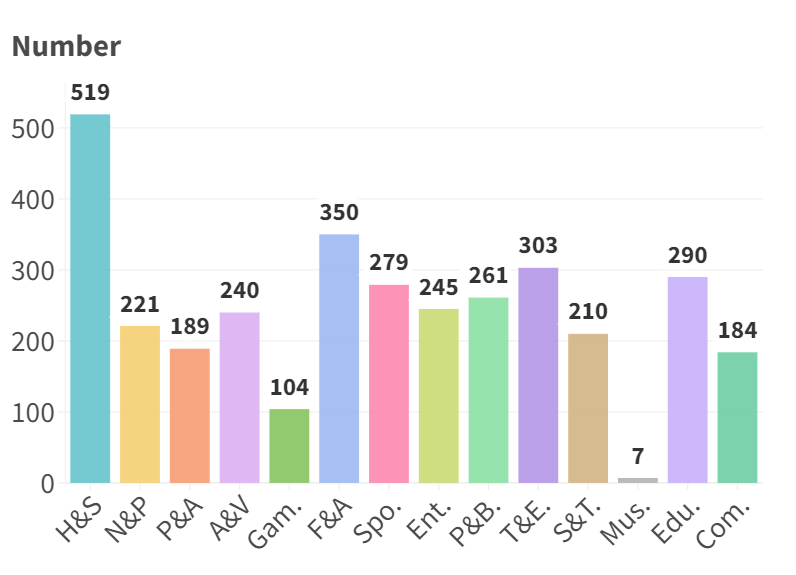
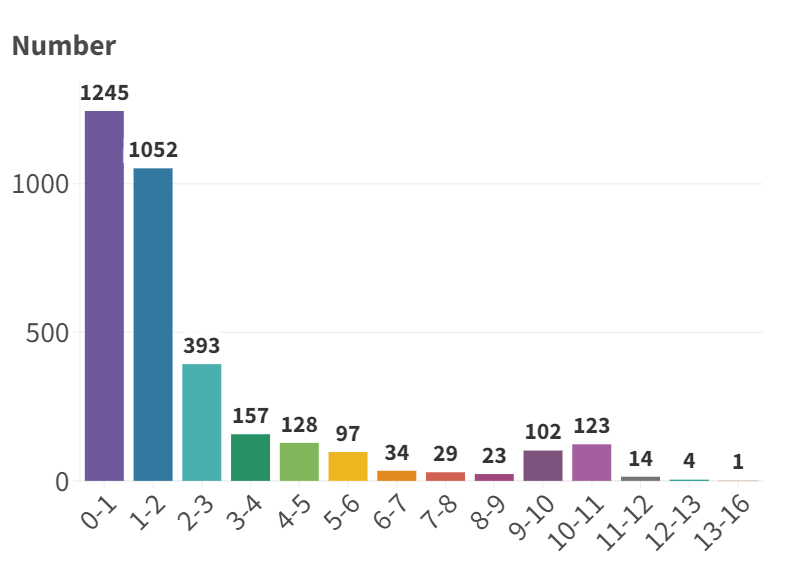
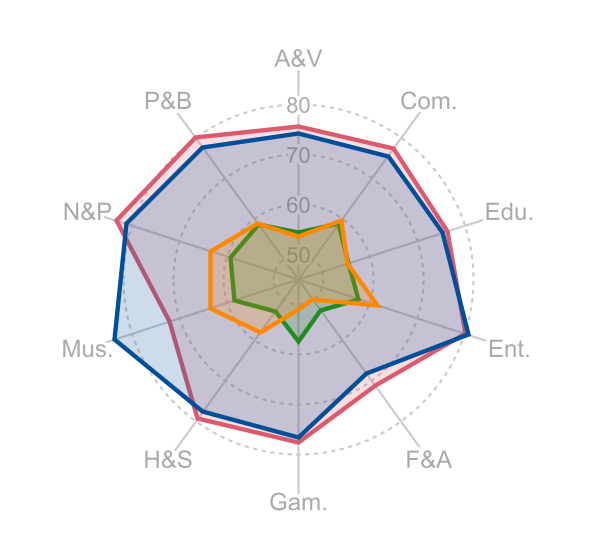
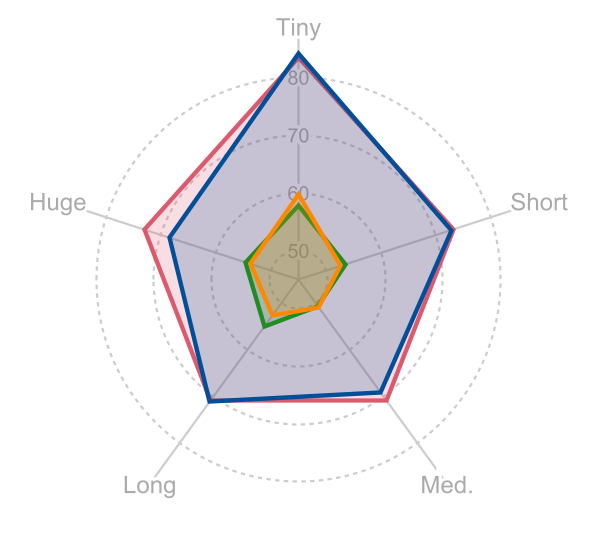
Accuracy scores on the VideoVista Dataset.
Unders.(Video Understanding Task); Reason.(Video Reasoning Task)
| # | Model | Language Model | Frames | Date | Overall | Unders. | Reason. |
| 1 | Human Performance | - | - | 2024-08-27 | 90.24 | 89.64 | 92.30 |
| 2 | LinVT | Qwen2-7B | 120 | 2024-12-26 | 79.67 | 77.31 | 87.84 |
| 3 | TimeMarker | - | 1fps | 2024-10-30 | 78.44 | 75.93 | 87.84 |
| 4 | GPT-4o | - | 100 | 2024-07-05 | 78.26 | 75.15 | 87.97 |
| 5 | Video-CCAM-v1.1 | Phi-3-medimum-4k | 96 | 2024-08-28 | 76.5 | 73.12 | 89.14 |
| 6 | Gemini-1.5-Flash | - | 1 fps | 2024-07-05 | 76.39 | 74.73 | 82.30 |
| 7 | GPT-4o-mini | - | 100 | 2024-07-19 | 75.76 | 72.87 | 85.52 |
| 8 | Qwen2-VL | Qwen2-7B | 1fps | 2024-09-02 | 75.56 | 72.58 | 85.89 |
| 9 | LLaVA-OneVision | Qwen2-7B | 32 | 2024-08-15 | 72.99 | 70.25 | 83.20 |
| 10 | Video-CCAM-v1.1 | Phi-3-mini-4k | 96 | 2024-08-26 | 70.82 | 67.49 | 82.31 |
| 11 | Kangaroo | Llama3-8B | 64 | 2024-07-24 | 69.5 | 66.36 | 81.23 |
| 12 | InternLM-XComposer-2.5 | InternLM2-7B | 64 | 2024-07-09 | 68.91 | 66.75 | 76.96 |
| 13 | Video-CCAM-v1.0 | Phi-3-medimum-4k | 96 | 2024-07-17 | 68.43 | 66.15 | 76.90 |
| 14 | Video-CCAM-v1.0 | Phi-3-mini-4k | 96 | 2024-07-18 | 68.09 | 66.18 | 75.22 |
| 15 | LongVA-DPO | Qwen2-7B | 128 | 2024-07-10 | 67.49 | 64.81 | 77.50 |
| 16 | LongVA | Qwen2-7B | 128 | 2024-07-08 | 67.36 | 64.67 | 77.39 |
| 17 | PLLaVA | Vicuna-13B-v1.5 | 16 | 2024-07-05 | 64.67 | 62.44 | 73.00 |
| 18 | VILA-1.5 | Vicuna-13B-v1.5 | 8 | 2024-07-07 | 64.18 | 62.27 | 71.34 |
| 19 | VideoChat2-Mistral-HD | Mistral-7B | 16 | 2024-07-17 | 61.58 | 59.27 | 70.24 |
| 20 | Uni-MoE | Vicuna-7B-v1.5 | 8 | 2024-07-05 | 61.13 | 58.65 | 69.62 |
| 21 | VideoLLaMA2 | Mistral-7B | 16 | 2024-07-05 | 60.47 | 58.73 | 66.97 |
| 22 | PLLaVA | Vicuna-7B-v1.5 | 16 | 2024-07-05 | 60.36 | 58.35 | 67.86 |
| 23 | VideoChat2-Mistral | Mistral-7B | 16 | 2024-07-05 | 57.24 | 54.91 | 65.95 |
| 24 | CogVLM2-Video-Chat | LLaMA3-8B | 24 | 2024-07-16 | 57.19 | 56.85 | 58.48 |
| 25 | LLaMA-VID | Vicuna-7B-v1.5 | 1 fps | 2024-07-05 | 56.87 | 54.00 | 67.61 |
| 26 | LLaVA-NeXT-Video-DPO | Vicuna-7B-v1.5 | 16 | 2024-07-05 | 56.66 | 54.12 | 66.14 |
| 27 | Video-LLaVA | Vicuna-7B-v1.5 | 8 | 2024-07-05 | 56.59 | 53.82 | 66.91 |
| 28 | VILA-1.5 | Llama3-8B | 8 | 2024-07-05 | 55.15 | 52.99 | 63.24 |
| 29 | MiniGPT4-Video | Mistral-7B | 45 | 2024-07-05 | 54.64 | 51.73 | 65.50 |
| 30 | VTimeLLM-Vicuna | Vicuna-7B-v1.5 | 100 | 2024-07-07 | 54.52 | 52.24 | 63.07 |
| 31 | Chat-UniVi-v1.5 | Vicuna-7B-v1.5 | 64 | 2024-07-08 | 54.22 | 51.72 | 63.55 |
| 32 | VideoChat2-Vicuna | Vicuna-7B-v1.5 | 16 | 2024-07-05 | 53.64 | 51.79 | 60.55 |
| 33 | ShareGPT4Video | Vicuna-7B-v1.5 | 16 | 2024-07-05 | 53.58 | 51.79 | 60.30 |
| 34 | VTimeLLM-ChatGLM | ChatGLM3-6B | 100 | 2024-07-07 | 52.86 | 50.91 | 60.15 |
| 35 | ST-LLM | Vicuna-7b-v1.1 | 64 | 2024-07-09 | 49.33 | 47.28 | 56.98 |
| 36 | MiniGPT4-Video | Vicuna-7B-v1.5 | 45 | 2024-07-05 | 44.92 | 43.43 | 50.48 |
| 37 | IVA | Vicuna-7B-v1.5 | 200 | 2024-07-05 | 39.7 | 37.38 | 48.38 |
| 38 | Video-ChatGPT | Vicuna-7B-v1.1 | 100 | 2024-07-05 | 36.65 | 36.09 | 38.73 |
| 39 | Video-LLaMA | Vicuna-7B-v1.1 | 16 | 2024-07-05 | 25.35 | 25.40 | 25.16 |
| 40 | VideoChat_with_ChatGPT | gpt-3.5-turbo | 40 | 2024-07-05 | 17.99 | 16.64 | 23.04 |